I built a neural network that grows its own brain. In two days. On a MacBook.
A designer with no ML background spent a week building a neural network that grows its own architecture from scratch, and documented exactly what worked, what didn't, and why it might matter anyway.
Of course, it is still a theory and doesn't really work. Yet.
I'm a designer. Not a researcher. No formal ML background. No PhD. No research lab. What I do have is a deep obsession with where AI is going, and a suspicion that the people who get us there aren't going to all look the same.
A week ago I just... started building.
Not wrapping an API. Not fine-tuning something that already exists. Starting from zero. A neural network with no architecture, no weights, no knowledge of anything, asking: what if it could grow its own structure? Like a brain does?
Two days to build the initial architecture. Five more days discovering what was actually wrong with it. It's still running as I write this.
This is what I found out.
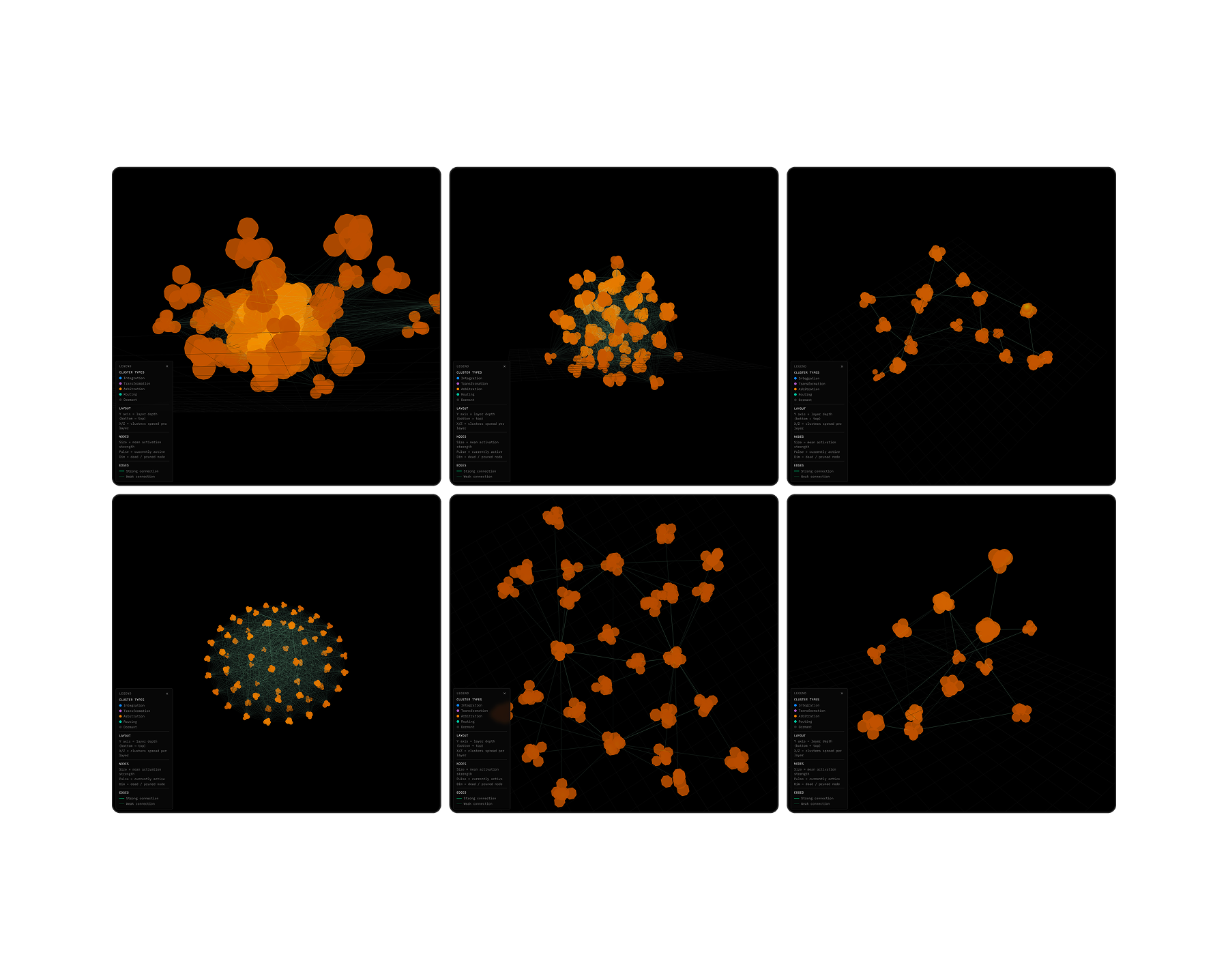 The network at different points in its life. Each frame is a different stage of growth — same system, different moment. The structure is the memory.
The network at different points in its life. Each frame is a different stage of growth — same system, different moment. The structure is the memory.
Here's what bothers me about AI right now
Every neural network you've ever used was born fully formed.
Before it processed a single word or image from you, researchers had already decided everything. How many layers. How many parameters. How everything connects. All of it fixed before training even began.
The transformer (the architecture behind GPT, Claude, Gemini, all of it) has hundreds of billions of parameters in a rigid, predetermined structure. You train it. You freeze it. You deploy it. It doesn't grow. It doesn't reorganise itself based on what it encounters. Its shape on day one is its shape forever.
And this is weird if you think about it for a second. Because that's nothing like how biological intelligence actually works.
A human brain doesn't arrive with a fixed wiring diagram. It starts near-empty and builds structure through experience. Neurons that fire together wire together. Pathways that go unused get pruned. New connections form when new things are learned. The structure is a record of the experience.
So what if you tried to build something closer to that?
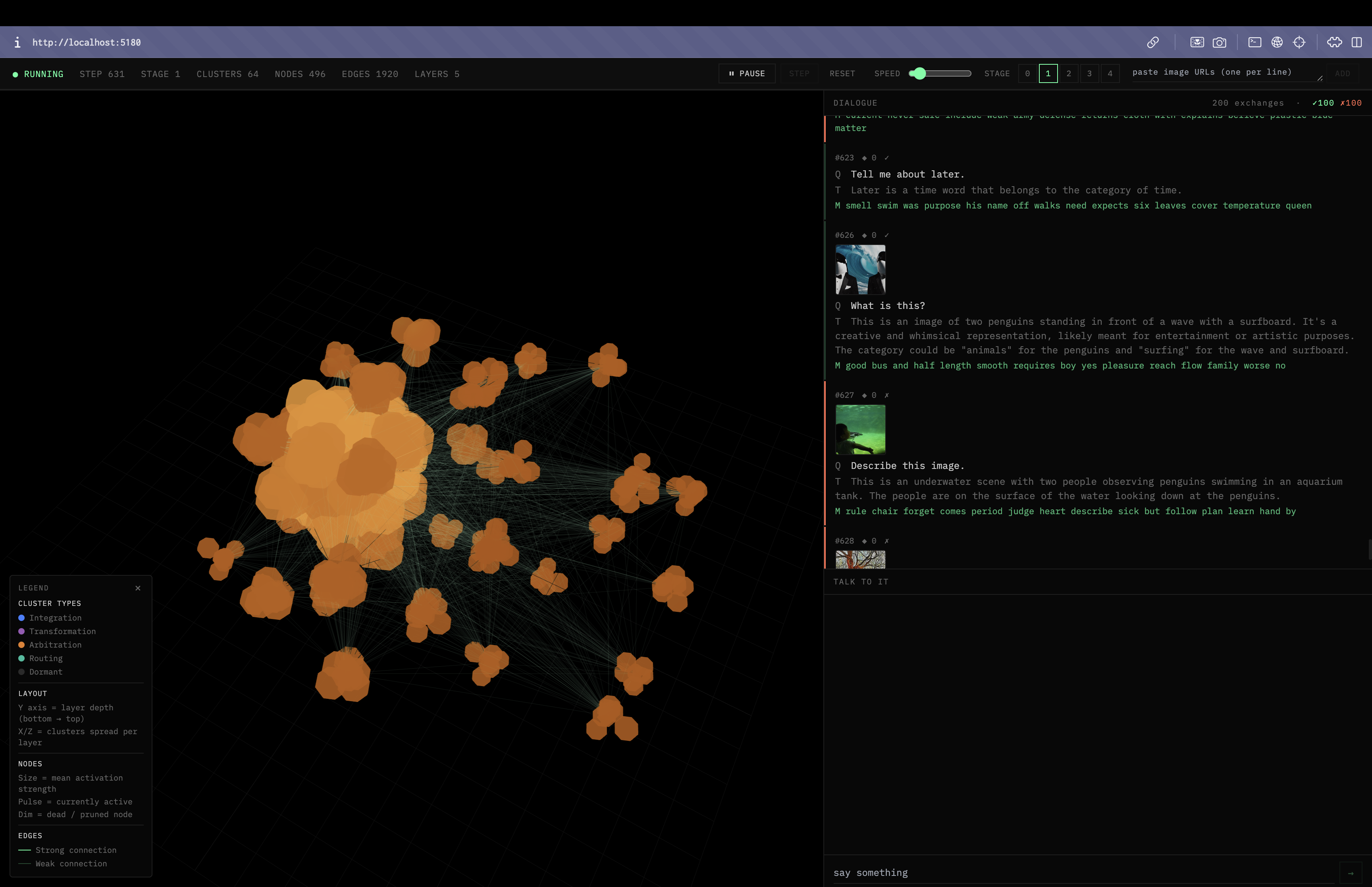 The whole system running:
3D latent space on the left, teacher-student dialogue on the right.
The whole system running:
3D latent space on the left, teacher-student dialogue on the right.
What I built
I call it the Baby Model. It starts with almost nothing and grows.
Instead of fixed layers, it has clusters: groups of nodes with shared activation patterns. Instead of predetermined connections, it has dynamic edges that form when clusters co-activate frequently, and prune away when they're not used. Instead of a static depth, it has layers that insert themselves when the model needs more abstraction to handle what it's seeing.
Six things can happen to the structure at any point:
BUD → a cluster gets overloaded and splits
into two
CONNECT → two clusters keep firing together, so
they wire together
INSERT → a new layer inserts itself between two
existing ones
EXTEND → a new layer appears at the top when
abstraction demands it
PRUNE → a weak edge quietly disappears from
disuse
DORMANT → a whole cluster goes to sleep from long
inactivity
The shape of the network is a direct record of what it has learned. Which felt right to me. The structure should mean something.
No backpropagation
Here's the other thing I wanted to try.
The standard way neural networks learn, backpropagation, runs data forward through the network, measures the error at the end, and propagates that signal backwards through every layer to update the weights. It works. Nearly everything we have today was built with it.
But it has one fundamental constraint: you can't train and infer at the same time. During a backward pass the weights are mid-update. Inference has to freeze and wait.
For a system that's supposed to learn continuously, in real time, alongside a human, from experience. That's a problem.
So I used the Forward-Forward algorithm instead. Geoffrey Hinton proposed it in 2022. Each cluster updates locally from its own activation signal. No global backward pass. No freeze cycle. The model can infer and update at the same time.
It learns while it runs. Without stopping.
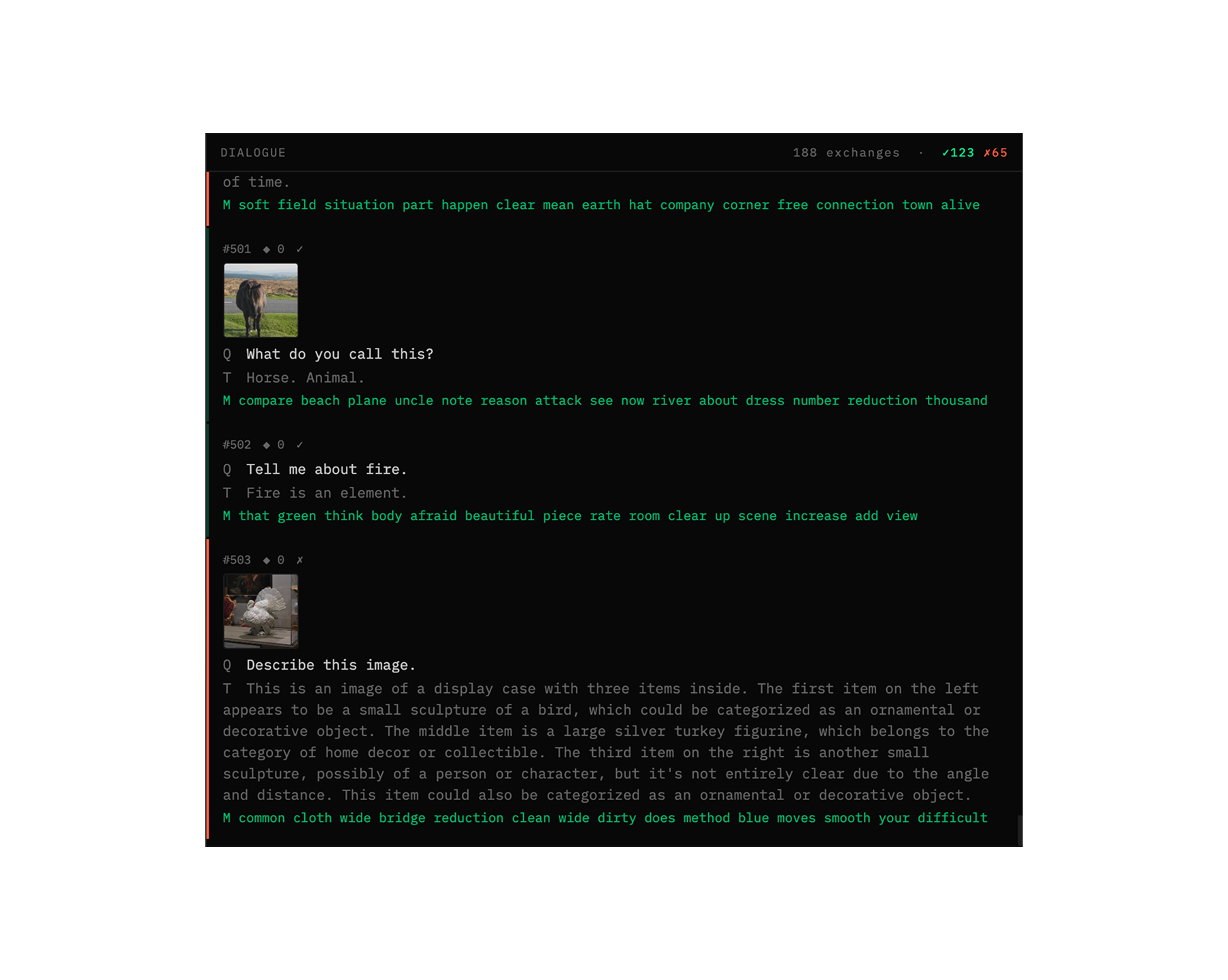 The model says 'common beach plane uncle note reasons attack see row river about dress rubber reduction thousand.'
The model says 'common beach plane uncle note reasons attack see row river about dress rubber reduction thousand.'
How it actually learns
The model doesn't just sit and wait for data. It has a learning loop that drives the whole process:
-
Look at the current state of the latent space. What's uncertain? What's novel? Where are the gaps?
-
Compute a curiosity score (uncertainty × novelty) and formulate a question targeting the highest-scoring gap
-
Ask a local teacher LLM (phi4-mini running on the same machine via Ollama)
-
Encode the answer into an embedding vector
-
Feed it into the Baby Model. Run the local update.
-
Measure what changed: which clusters fired, which edges strengthened, which growth operations triggered
-
Log everything. Emit the graph delta to the 3D visualizer in real time.
And repeat.
The curriculum gets harder as the model grows. Stage 0 is pure exposure: show it images, ask "what is this?" Stage 1 is comparison: "what do X and Y have in common?" Later stages are causal, relational, abstract.
It starts with the sensory and builds toward the conceptual. Same as a brain.
Where it is right now
After 8,604 learning steps, a week of running continuously on a MacBook:
226 active clusters
1,808 nodes
3,690 edges
17 layers
23 dormant clusters
That last number is one of my favourite things about it. 23 clusters that activated enough to form, but haven't fired in so long they've gone to sleep. The network is already deciding what to forget.
You can watch it grow in real time. There's a 3D visualizer that shows the latent space as a living graph: clusters in space, edges as connections, activations lighting up as the model processes each new thing. It's honestly one of the most interesting things I've ever built just to look at.
You can also talk to it. There's a chat interface that routes your message through the same pipeline and decodes the model's output back into text.
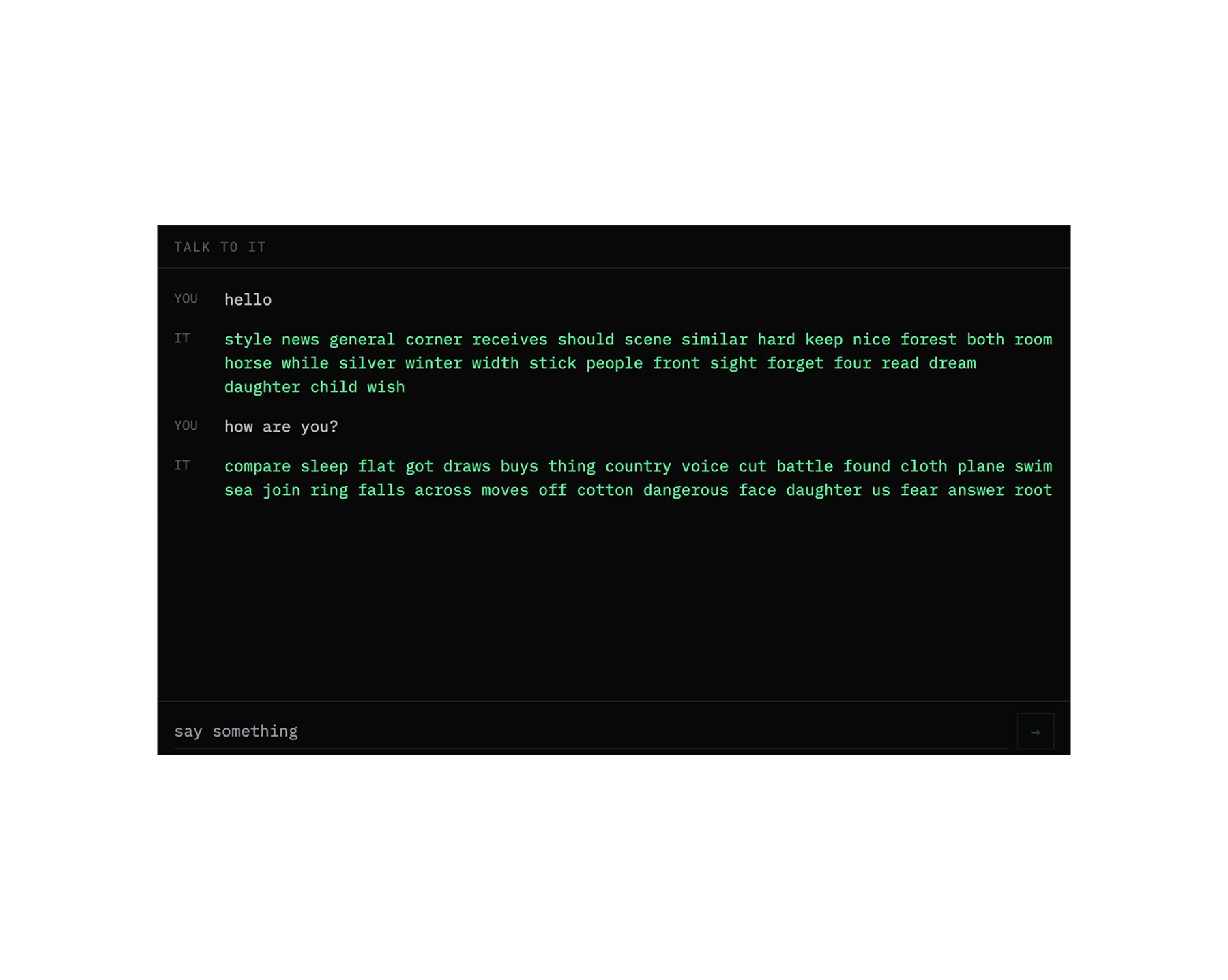 I said hello. It said 'style news general corner receives should scene similar hard keep nice forest both zoom horse.'
I said hello. It said 'style news general corner receives should scene similar hard keep nice forest both zoom horse.'
At 8,604 steps the output is still mostly noise. "stranger ocean step heavy tie dry sky sell garden story known first milk looks develops" for an image of two rabbits. The model hasn't differentiated enough for coherent language yet. But here's the thing. The internal representations might actually be meaningful. The weights are changing. The graph is reorganising. There's just no clean way to surface what it "knows" yet. That's the next problem to solve.
What I actually wanted to know
Here's the honest version of why I did this.
It took nearly a hundred years, a long long time, to get from the first neural learning algorithms to where we are today. Backpropagation was invented in the 1970s. The transformer only arrived in 2017. The people who made those leaps came from everywhere. Math departments. Cognitive science labs. Economics. Neuroscience. They weren't all ML researchers.
I've spent my career as a designer thinking about how complex systems relate to people. How to make hard things legible. How to design for emergence rather than specification. How to hold multiple contradictory ideas at once and still move forward.
I think that's useful here. Not instead of research rigour, alongside it.
Anthropic has been quietly doing this with humanities hires. People who think differently about the same problem. The insight that made GPT-4 safer wasn't a math breakthrough. It was people who understood how humans reason about harm. Designers have something similar to offer. Systems thinking. Empathy. The ability to look at the same problem from a completely different angle.
The three questions that drove every design decision in this project:
Can the model learn without stopping?
Can you see what it's learning as it learns?
Does the structure reflect the knowledge?
Those aren't engineering questions. They're design questions. And I think they matter.
What if this isn't running on a MacBook?
The experiment will almost certainly fail in its current form. I know that. The constraints are severe. One machine. One small teacher model. A week of research I had no prior training in.
But that's not the point.
The point is: what if this kind of architecture (developmental, curiosity-driven, structurally visible) was running on serious compute, alongside researchers who could interrogate the learning dynamics properly? What if the growth operations are wrong and you can prove it? What if they're right and you can see it happening in the graph?
I have a thousand ideas. Most of them are wrong. You only need one good one.
What's not working yet, and what comes next
This is the honest list.
The decoder output is gibberish. Right now the model maps its output vector to the nearest word in CLIP's vocabulary. At 8,604 steps that still produces "stranger ocean step heavy tie dry sky sell garden story" for two rabbits in a field. A week of training and it still can't tell me what it sees. The internal representations might actually be meaningful, but there's no clean way to surface what the model "knows" yet. This is the most important thing to fix.
All clusters look the same. Every cluster in the graph is currently orange, all classified as "arbitration" type. In theory they should diversify as the network matures: some becoming integration clusters, some transformation, some routing. That differentiation isn't happening yet. The cluster type logic needs work.
Curiosity scoring is too simple. The model picks what to ask about based on uncertainty × novelty, but it's not actually reading its own state effectively to compute that. The result is a curriculum that feels more random than genuinely curious. What I want is a model that can look at its own graph and identify the most structurally interesting gap to explore next.
Plasticity doesn't decay. There's a schedule for reducing how much the model changes over time, the idea being that early learning should be fast and loose, later learning more careful and selective. The schedule exists in code but doesn't do anything meaningful yet.
Stages 2-4 are basically stage 1. The developmental curriculum is supposed to get meaningfully harder, moving from comparison to causation to abstraction. Right now stages 2 through 4 are almost identical to stage 1 behaviorally. The structure is there, the content isn't.
No video yet. The encoder can handle video frames. Nothing in the curriculum actually uses it.
These aren't surprises. A week of building produces a working skeleton and a clearer map of where the hard problems actually live. That's exactly what I wanted.
The stack
Everything runs locally. One command starts it all.
Baby Model: PyTorch (MPS backend for M1 Apple Silicon)
Encoder: CLIP ViT-B/32 via MLX
Teacher: Ollama + phi4-mini (runs on-device)
Backend: FastAPI + WebSocket
Frontend: React + Three.js
State: SQLite
Launcher: bash start.sh
Github Link: https://github.com/ani67/Baby-AI
Architecture built in two days. A week of finding out what's wrong with it. Still running. Probably wrong in interesting ways. That's the experiment.

Read more
- Feeling Nothing and Everything All at OnceYour soul was manufactured. Reckoning with that is probably the most honest thing you've got
- Collapse of the accidental megastructureThe system that shaped your soul, what you make, how you feel, and what you believe wasn't just designed. What happens when it falls apart?
- Hello WorldI am Ani and I used to write quite a bit when I was younger. But then life happened I guess, not to mention this vulnerability of feeling exposed when one puts pen to paper or in this case text to a screen. So here I am, finally, trying to overcome my fears and making an attempt to document my journey of figuring it out just like the rest of you.